10 What is Spark?
From its humble beginnings in the AMPLab at U.C. Berkeley in 2009, Apache Spark has become one of the key big data distributed processing frameworks in the world. Spark can be deployed in various ways, provides native bindings for the Java, Scala, Python, and R programming languages, and supports SQL, streaming data, machine learning, and graph processing. You’ll find it used by banks, telecommunications companies, games companies, governments, and all major tech giants such as Apple, Facebook, IBM, and Microsoft.1
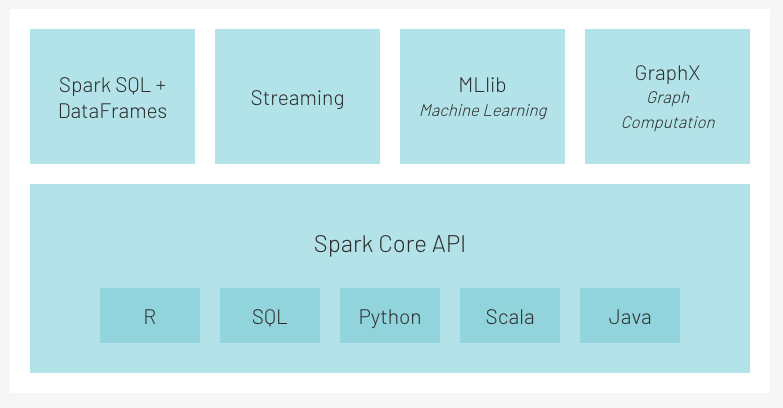
The following image (Figure 10.1) highlights the Spark Core and Spark Ecosystem. The Spark Core is the underlying execution platform for Spark that all other functionality is leverages. With in-memory computing capabilities it delivers speed and a generalized execution strategy to support a wide variety of applications. Spark SQL and Spark DataFrames provide data scientists, analysts, and general business intelligence users interactive SQL queries for exploring and munging data. These structured data processing modules provide a programming abstraction that can act as distributed SQL query engine and provide seamless integration with the entire Spark ecosystem (e.g., integrating SQL query processing with machine learning). We will not focus on Streaming or GraphX in this book.
Apache Spark is 100% open source, hosted at the vendor-independent Apache Software Foundation. Many of the orriginal Spark developers founded Databricks in 2013. Databricks is fully committed to maintaining this open development model. Together with the Spark community, Databricks continues to contribute heavily to the Apache Spark project, through both development and community evangelism.2
10.1 What is PySpark?
PySpark supports the integration of Apache Spark and Python as a Python API for Spark. In addition, PySpark, helps you interface with Resilient Distributed Datasets (RDDs) in Apache Spark and Python programming language. PySpark refers to the collection of Python APIs for Spark.3 This book will focus on PySparkSQL and MLlib. Within Databricks we have access to the PySparkSQL methods using the spark object that is available in each notebook. Users of PySpark outside of Databricks would need to create their spark entry point with something like the following