11 Feature Engineering
When working with business data, we often have a database that stores transactions. We will have tables that store credit card transactions, tables that store paycheck transactions, key card tables that store build access transactions, and account tables that store logins or purchase transactions. These transaction tables are usually not at the right level of detail (often called ‘unit of analysis’) for any machine learning or statistical model inference.
To build our predictive models, these transaction tables need to be munged into the correct space, time, and variable aggregation. Here are the questions we must work through based on our modeling needs.
- What is my spatial unit of interest for predictions? How can I munge my tables to create the foundation of the analysis table?
- What is my label/target that I will use for prediction?
- What features would help predict my label?
- What is my temporal unit of interest for feature building?
- What tables/keys do I need to map my transactions to that spatial unit?

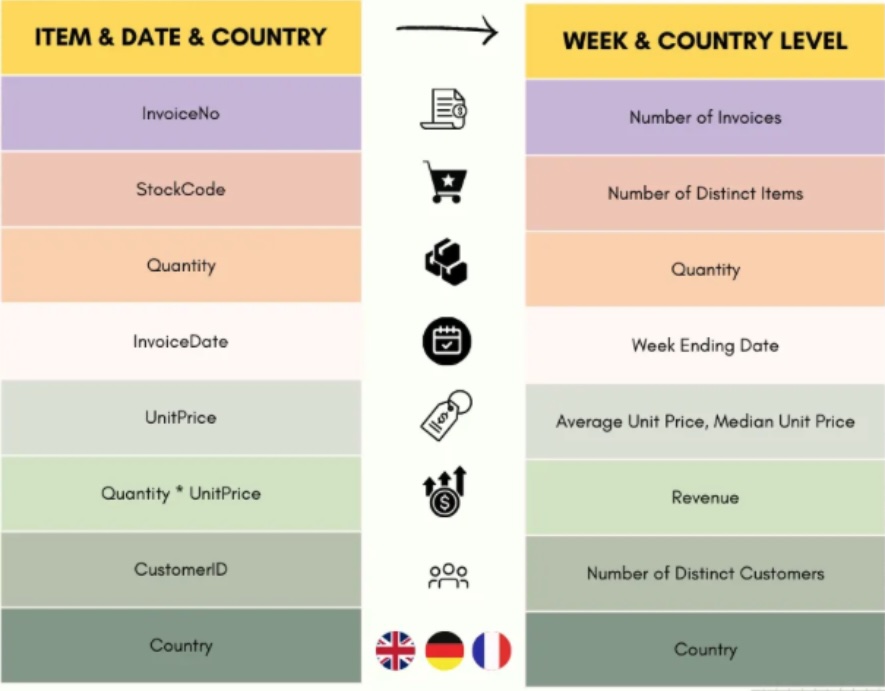
Soyoung L1 shared the following image in her Medium post on feature engineering. Notice the examples of moving from transaction data to the unit of analysis level of data that we would use in our modeling.
While there is a lot of engineering when building features for models. There is also a lot of art.
Feature engineering is more of an art than a formal process. You need to know the domain you’re working with to come up with reasonable features. If you’re trying to predict credit card fraud, for example, study the most common fraud schemes, the main vulnerabilities in the credit card system, which behaviors are considered suspicious in an online transaction, etc. Then, look for data to represent those features, and test which combinations of features lead to the best results.2
The following image provides a comical view of the comparison between machine learning and feature engineering.
